Using LangChain with Azure OpenAI to implement load balancing via fallbacks
Table of Contents
Introduction #
In this article we’ll be looking into two simple and quick ways to implement a “kind-of load balancing” for Azure OpenAI using LangChain. In my last poste A Guide to Azure OpenAI Service’s Rate Limits and Monitoring we discussed how rate limits can negatively affect throughput and latency when running completions, so in this post we’ll dive deeper into two practical solutions.
Both approaches outlined in this post achieve similar results as using an external load balancer, but are significantly easier to implement when using LangChain. However, neither approach splits up the load between multiple instances equally (e.g., using round-robin). Instead, they shift the load to a subsequent model once the current one hits its limit.
Solutions #
To run the code examples, make sure you have the latest versions of openai and langchain installed:
pip install openai --upgrade
pip install langchain --upgrade
In this post, we’ll be using openai==0.27.9 and langchain==0.0.271.
Falling back to a larger model #
One simple way to deal with the token or rate limit is to use a different or larger model when this happens. The rational behind it is that larger models often give larger token limits per minute (so for example does Azure). So instead of retrying and waiting for the same model to become “useable” again, we just switch to a larger model.
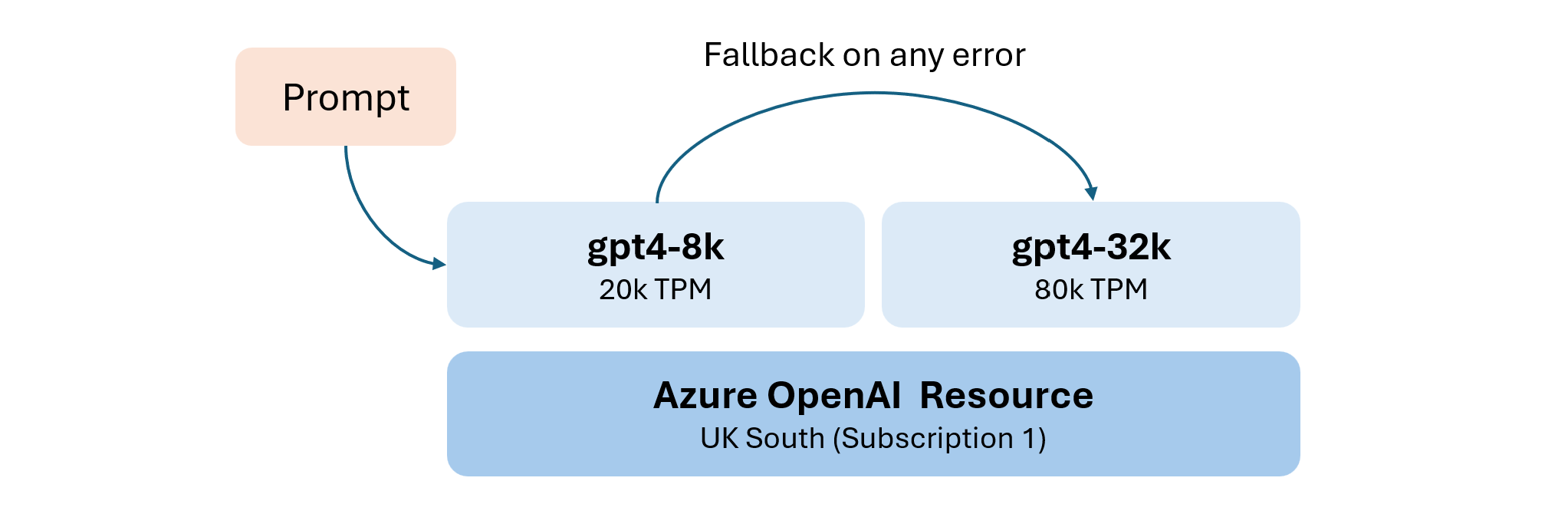
This approach is especially useful when using gpt4 on Azure OpenAI as the default TPM (token per minute) limit for gpt4-8k is only 20k TPM. However, since we get an additional 60k TPM for gpt4-32k, why not use them? Surely, there is some additional, higher cost associated with this (the 32k model is more expensive for both prompt and completion tokens), but if throughput is the limiting factor, this is an easy fix.
To get this going, let’s first make sure we have both models deployed: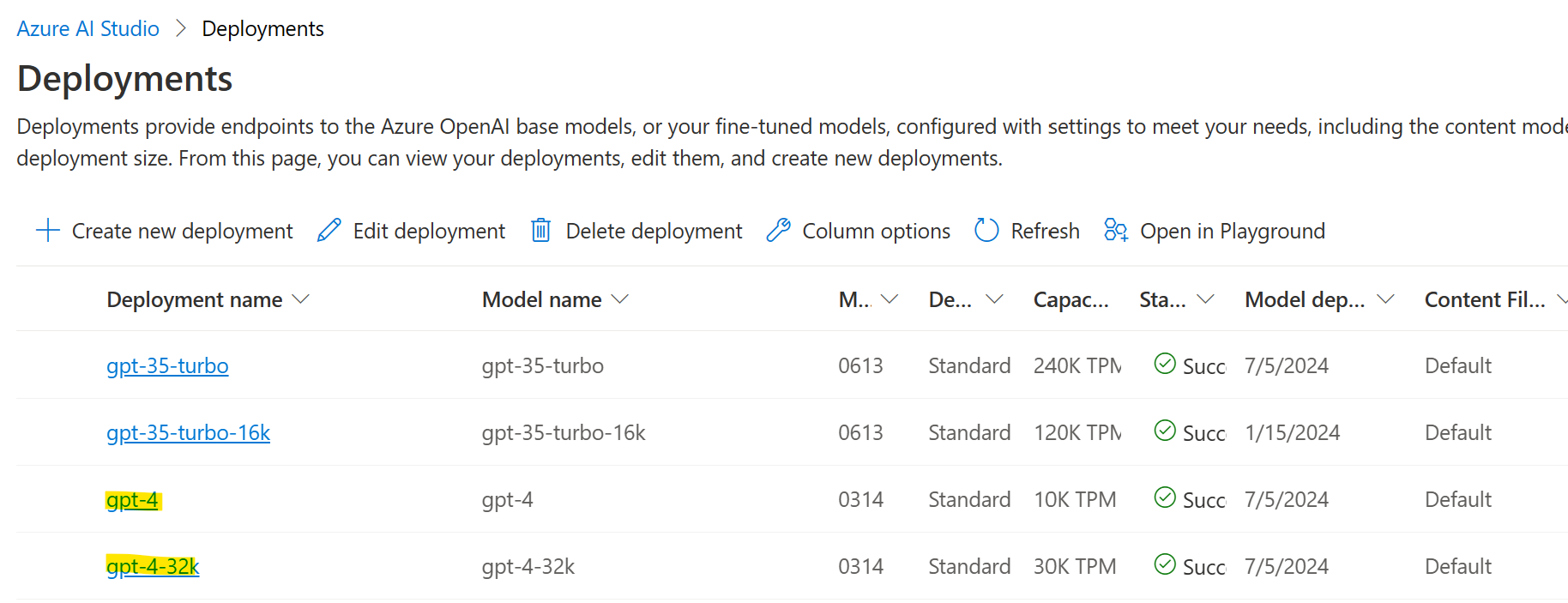
Then create an .env with the credentials to the endpoint:
AOAI_ENDPOINT_01=https://xxxxxxx.openai.azure.com/
AOAI_KEY_01=xxxxxx
And lastly run the following Python code:
import os
from dotenv import load_dotenv
from langchain.chat_models import AzureChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
load_dotenv()
kwargs = {
"openai_api_type": "azure",
"openai_api_base": os.getenv("AOAI_ENDPOINT_01"),
"openai_api_key": os.getenv("AOAI_KEY_01"),
"openai_api_version": "2023-05-15",
"temperature": 0.7,
"max_tokens": 100
}
# Create a connection to gpt4-8k and gpt4-32k models
llm_8k = AzureChatOpenAI(deployment_name="gpt4-8k", max_retries=0, **kwargs)
llm_32k = AzureChatOpenAI(deployment_name="gpt4-32k", **kwargs)
# This is where the magic happens
llm = llm_8k.with_fallbacks([llm_32k])
system_message_prompt = SystemMessagePromptTemplate.from_template("You are an AI assistant that tells jokes.")
human_message_prompt = HumanMessagePromptTemplate.from_template("{text}")
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chain = chat_prompt | llm
for i in range (1,10):
result = chain.invoke({"text": "Tell me a dad joke"})
print(result)
Easy! This code will run happily and choose the 8k model, but in case it fails (we set max_retries=0), it will fall back to the 32k model and will keep retrying until it gives up (per default 6 tries). All we needed to do was create an AzureChatOpenAI for each model, and then configure the fallback. The remainder of the LangChain code stayed the same, so adding this to an existing projects is pretty easy. The other benefit is that it allows to use higher level concepts like ConversationalRetrievalChain in LangChain.
In summary, this approach has the following benefits:
- Only requires one Azure OpenAI resource
- Great for
gpt4, where the quota is lower and quota increases are harder to get
Its downsides are:
- Typically more costly
- Limited scalability (mostly due to the fact that getting access to
gpt4can still take some time) - Does not solve the noisy neighbor problem
Falling back to multiple, but the same models #
If we do not want to use a larger model, we can try an equally simple approach: falling back to the same model, but deployed in a different region and/or subscription.
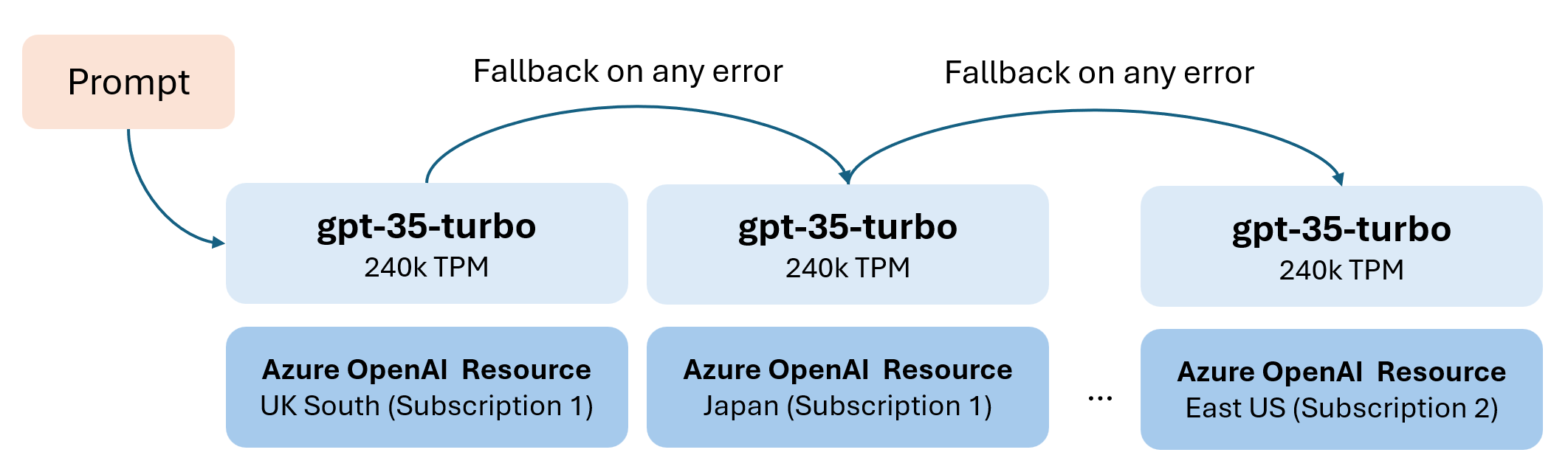
For example, with gpt-35-turbo we’ll get 240k TPM per subscription and region, so we if leverage four regions at once, we get close to 1m TPM (at least theoretically)! All we need to do is create an Azure OpenAI resource in each region and deploy our gpt-35-turbo model.
For this, create an .env pointing to our Azure OpenAI endpoints in the different regions (could be all in the same or different subscriptions):
AOAI_ENDPOINT_01=https://xxxxxxx.openai.azure.com/
AOAI_KEY_01=xxxxxx
AOAI_ENDPOINT_02=https://xxxxxxx.openai.azure.com/
AOAI_KEY_02=xxxxxx
AOAI_ENDPOINT_03=https://xxxxxxx.openai.azure.com/
AOAI_KEY_03=xxxxxx
Next, let’s fire up Python:
import os
from dotenv import load_dotenv
from langchain.chat_models import AzureChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
load_dotenv()
# get all credentials for connections from .env
keys = []
for key, value in os.environ.items():
if key.startswith("AOAI_ENDPOINT_") and value is not None:
num = key.split("_")[-1]
keys.append((value, os.environ[f"AOAI_KEY_{num}"]))
# Init connections to LLMs
llms = [AzureChatOpenAI(openai_api_type="azure",
openai_api_base=x[0],
openai_api_key=x[1],
openai_api_version="2023-05-15",
deployment_name="gpt-35-turbo",
temperature=0.7,
max_tokens=100,
max_retries=0) for x in keys]
# Let's keep the last LLM as the backup with retries, in case all other LLMs failed
llms[-1].max_retries = 6
# Create our main LLM object that can fall back to all other LLMs
llm = llms[0].with_fallbacks(llms[1:])
# Perform prompting as normal
system_message_prompt = SystemMessagePromptTemplate.from_template("You are an AI assistant that tells jokes.")
human_message_prompt = HumanMessagePromptTemplate.from_template("{text}")
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chain = chat_prompt | llm
for i in range (1,10):
result = chain.invoke({"text": "Tell me a dad joke"})
print(result)
Same as before, we use the with_fallbacks() option from LangChain to fall back to the next model, then the next model, and so on. For the last model, we keep the max_retries at 6 in order to have a last resort for retries.
In summary, this approach has the following benefits:
- Very large scalability
- Might solve the noisy neighbor problem, in case other regions are less crowded (requires to set a low
request_timeout)
Its downsides are:
- Requires multiple Azure OpenAI resources, potentially multiple subscriptions
Considerations #
When using either strategy, it’s vital to determine the specific scenarios where the with_fallbacks() method comes into play. For instance, in our provided example, we default to a fallback during any error. However, in some scenarios, you might want to activate this only during token or rate limiting incidents. This customization can be done seamlessly by incorporating the exceptions_to_handle parameter.
Another aspect to keep an eye on is defining the request_timeout for the model. To prevent prolonged API interactions, consider an immediate transition to an alternative model after a stipulated timeout, say 10 seconds. This can be realized by initializing the AzureChatOpenAI() connections using the request_timeout=10 parameter.
Lastly, it’s always prudent to surround our Azure OpenAI interactions with a try/catch mechanism, ensuring a safe exit strategy should any unexpected issues arise.
Key Takeaways #
In this article, we’ve explored two straightforward methods to establish fallback strategies with LangChain, effectively circumventing token or rate limitations in Azure OpenAI. While these methods excel in addressing token or rate restrictions, if your goal is to delve into genuine load-balancing at the http level, I recommend reading this detailed post.